Fakten vernetzen mit FactGrid
Ein Projekt zur modellhaften Erfassung historischer Daten in einer offenen Wissensdatenbank.
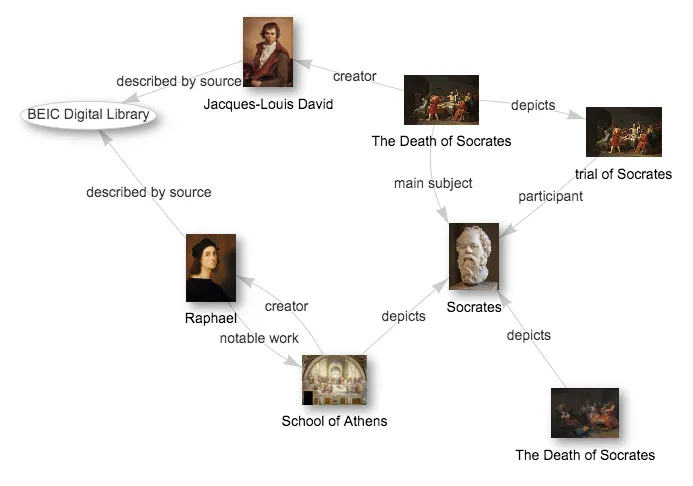
In den Digital Humanities fehlen bislang integrierte Lösungen für einen geschlossenen Forschungsdatenzyklus. HisQu entwickelt eine fachspezifische Anwendung, um diesen Mangel zu beheben und den gesamten Forschungsprozess für historische Quellen digital zu unterstützen.
Ein lückenloser Prozess
In den digitalen Geisteswissenschaften dominieren bislang digitale Editionen und punktuelle „Insel-Lösungen“ – Tools und Skripte, die nur für ein spezifisches Forschungsproblem entwickelt wurden. Ein geschlossener digitaler Forschungsdatenzyklus fehlt, wodurch Nachvollziehbarkeit, Reproduzierbarkeit und nachhaltige Archivierung oft nicht gewährleistet sind. HisQu setzt hier an und entwickelt eine fachspezifische Lösung, die historische Quellen und Forschungsprozesse gezielt digital unterstützt und den Forschungsworkflow nahtlos zusammenführt.

Das Repertorium Germanicum (RG) erschließt die in den päpstlichen Registerserien überlieferten Bezüge zum Heiligen Römischen Reich (Personen, Orte, Institutionen, Rechtsakte). Es bildet damit eine der zentralen Grundlagen für prosopographische und regionalhistorische Analysen der spätmittelalterlichen Kurie und ihrer Kommunikations- und Interaktionsräume.
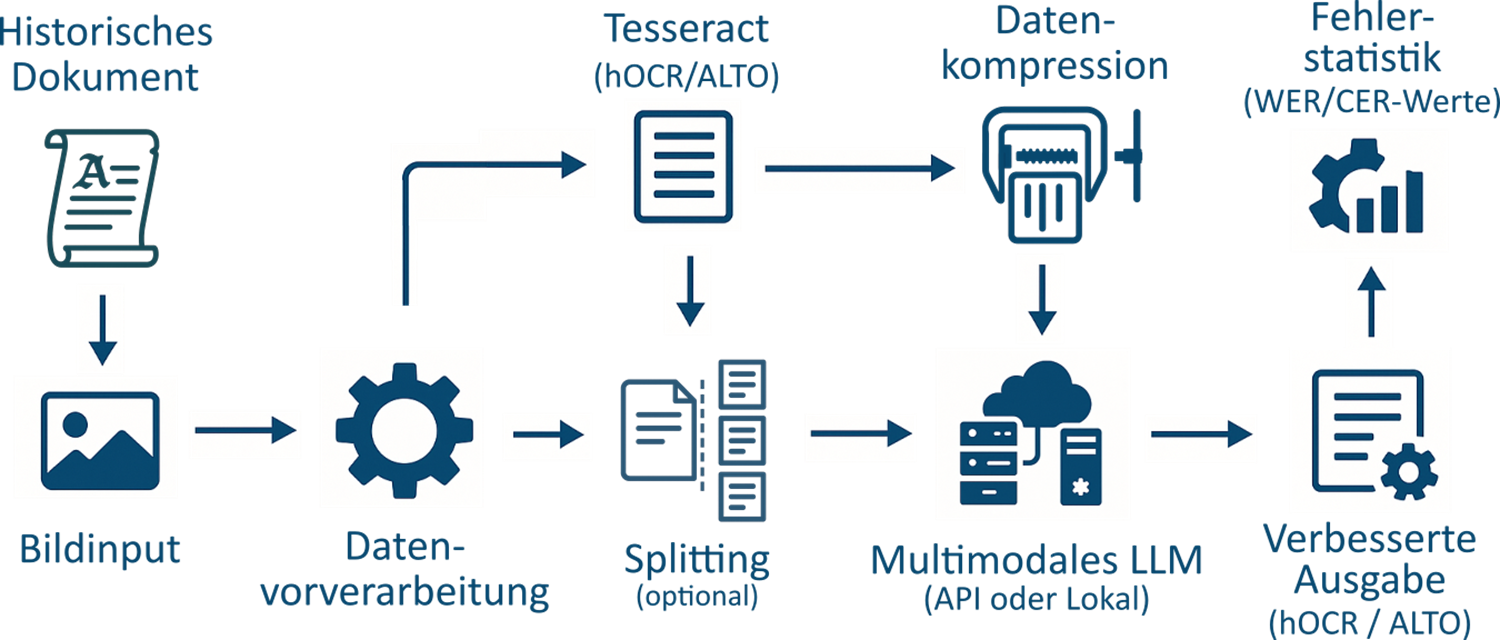
HisQu zielt darauf ab, die Digitalisierung gedruckter historischer Quellen mit anspruchsvollen Layouts – etwa Frakturschriften oder komplexen Spaltenstrukturen – deutlich zu verbessern. Dafür erweitern wir klassische OCR-Tools wie Tesseract durch den Einsatz von LLMs: Diese übernehmen die Vorverarbeitung der Quellen mithilfe von Bounding Boxes und ermöglichen zugleich eine nachträgliche Korrektur der Ergebnisse.
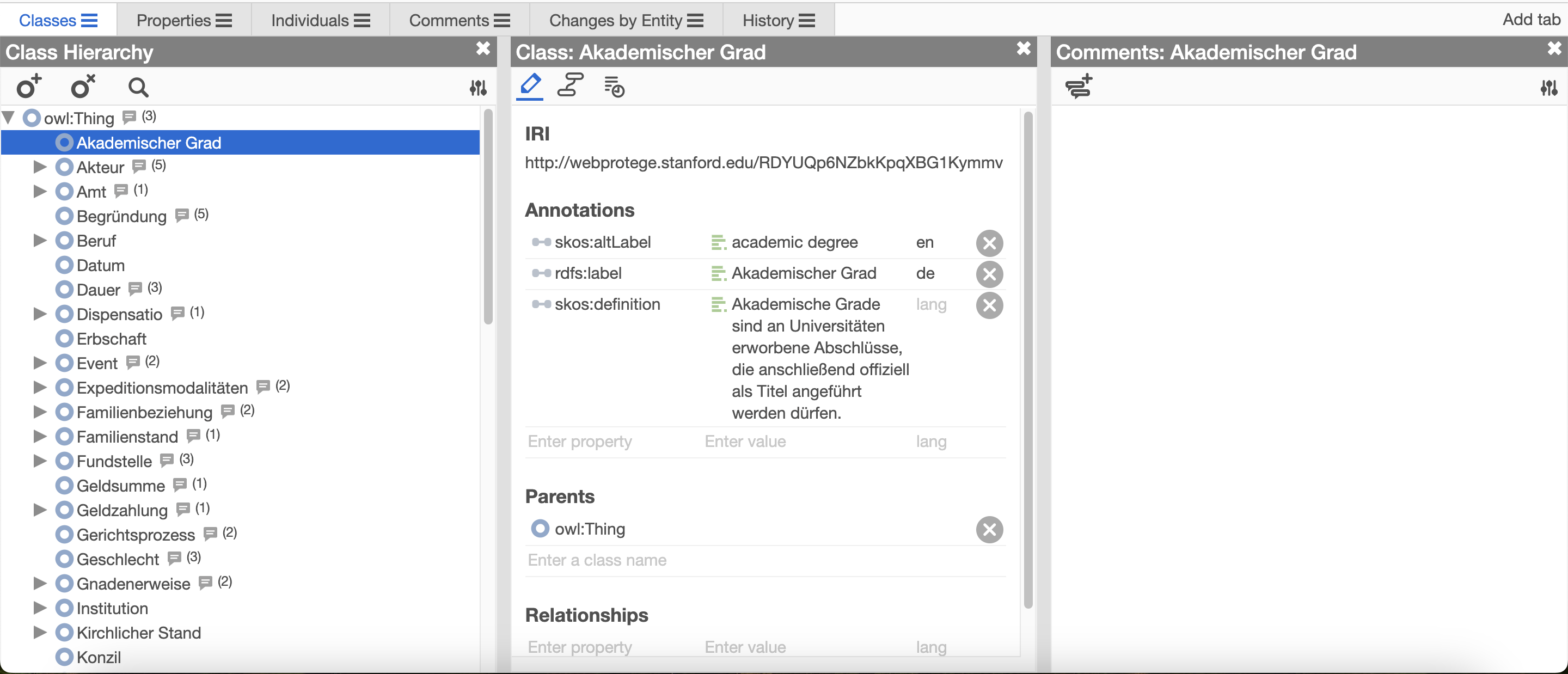
Die konsequente Digitalisierung geschichtswissenschaftlicher Forschungsprozesse erfordert domänenspezifische Vokabulare. Nur so lassen sich Quellen und Forschungsaussagen semantisch erfassen und interoperabel machen. HisQu setzt hierfür auf Wissensgraphen, die sowohl die Ontologie als auch die damit formulierten inhaltlichen Aussagen gleichberechtigt abbilden. Dieses Modell schafft Flexibilität für die digitale Modellierung und die Weiterentwicklung fachlicher Expertise. Grundlage dafür ist die Arbeit mit Protégé.
Für die Datenverarbeitung entwickelt HisQu innovative Tools auf Basis von LLMs. Mit Paredros steht Historiker:innen eine Grammatikentwicklungsumgebung zur Verfügung, die bei der Formulierung von Grammatiken zur Auswertung von Quellen unterstützt. Ergänzend entsteht mit OPA (Ontology Parser Assistant) ein Python-basierter LLM-Client, mit dem Ontologie-Snippets erstellt und flexibel erweitert werden – eine Grundlage für die semantische Modellierung und Weiterentwicklung domänenspezifischen Wissens.
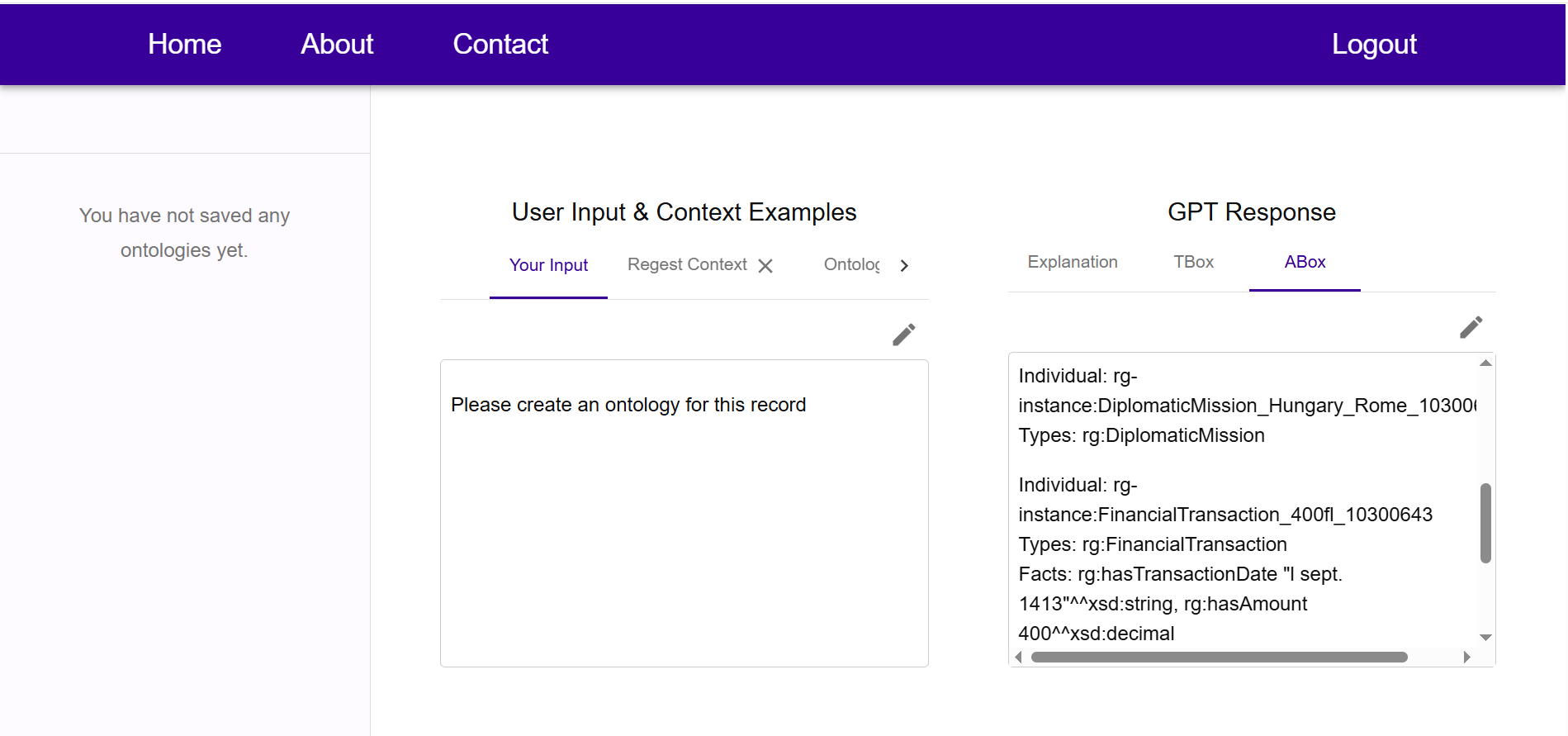
Um den Zugang zu komplexen SPARQL-Abfragen zu erleichtern, entwickelt HisQu einen grafischen Query-Builder. Dieser ermöglicht es, Abfragen intuitiv zusammenzustellen und zugleich den generierten SPARQL-Code einzusehen. Perspektivisch wird zudem eine Anbindung an ein LLM integriert, um die Erstellung und Anpassung von Abfragen noch benutzerfreundlicher zu gestalten.
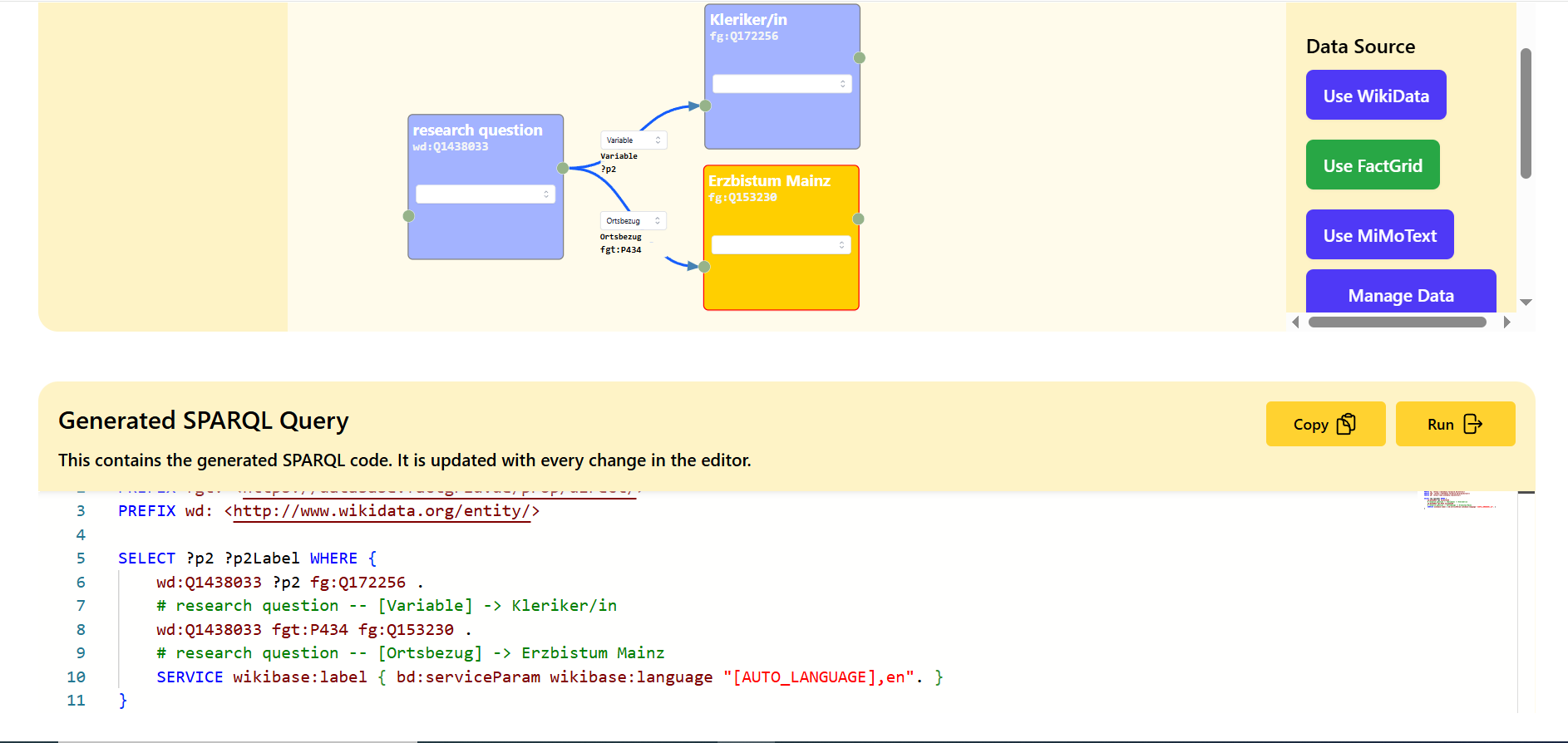
Beispiel einer Abfrage zu allen Klerikern mit Ortsbezug zur Diözese Mainz – oben erfolgt der Aufbau über die grafische Oberfläche, unten die Ausgabe des entsprechenden SPARQL-Codes.
Für die Speicherung der Daten nutzt HisQu FactGrid, eine speziell auf die Bedürfnisse der Geschichtswissenschaft zugeschnittene Wikibase-Instanz. Sie ermöglicht kollaboratives und nachvollziehbares Arbeiten mit Klarnamen. Alle aktiven Mitwirkenden erhalten personalisierte Konten, die eindeutig über ORCID-IDs verknüpft sind. Auf diese Weise entstehen zitierfähige (Mikro-)Publikationen, die die Sichtbarkeit und Akzeptanz von HisQu in der wissenschaftlichen Community stärken.
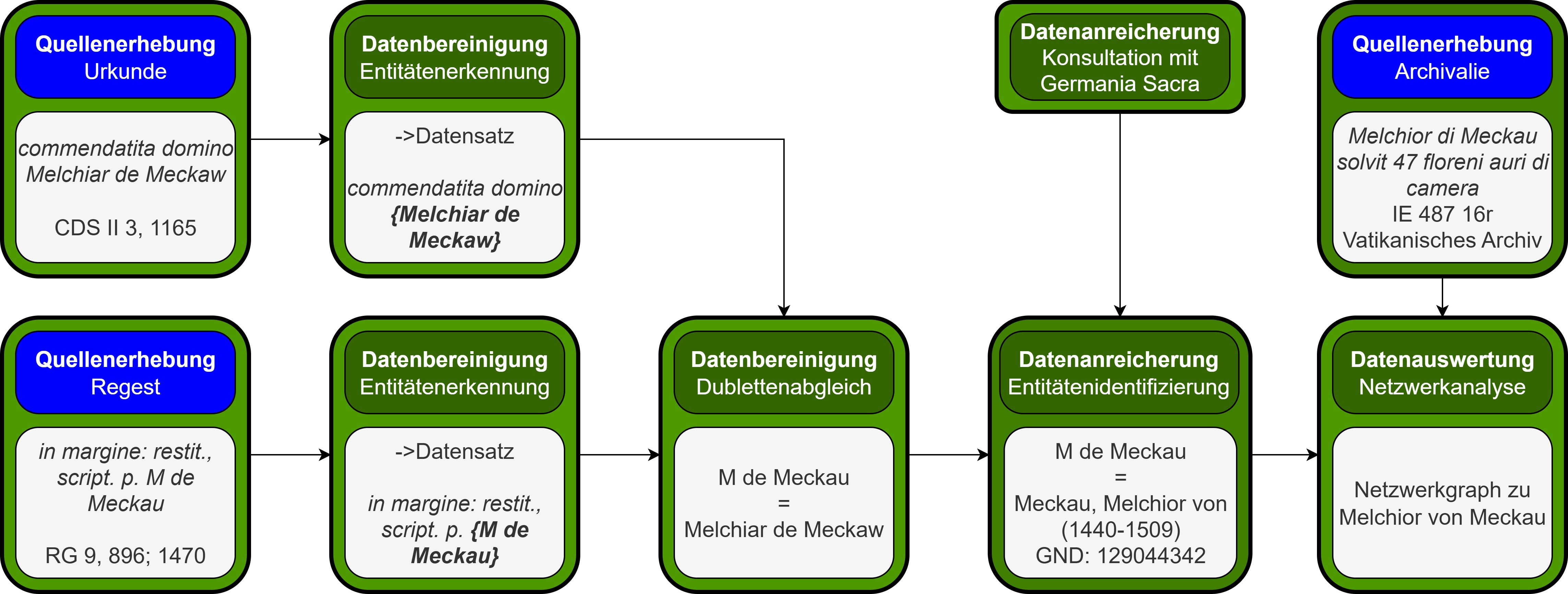
HisQu entwickelt ein interaktives Labortagebuch, das historische Forschungsprozesse transparent und reproduzierbar macht. Dafür werden abstrakte Dokumentationsbausteine wie Datenerhebung, -auswertung oder Visualisierung definiert und in einer graphischen Oberfläche zu konkreten Workflows zusammengesetzt. Ein visueller Editor bildet die einzelnen Schritte samt Abhängigkeiten ab und ermöglicht ihre Verwaltung mit zeitgemäßen Werkzeugen wie Git-Integration und automatisch generiertem Wiki.
Partner im Verbund
HisQu wird von führenden Einrichtungen der Digital Humanities und Geschichtswissenschaft getragen. Der Verbund verbindet methodische Exzellenz in Computerlinguistik und Wissensgraphen mit langjähriger Editionserfahrung und Forschungsdaten-Kompetenz.

FSU Jena
Prof. Dr. Clemens Beckstein · Apl. Prof. Dr. Robert Gramsch-Stehfest
Methodische Führung in Modellierung, Erklärung und Prozessen historischer Wissenschaften – von semantischer Erschließung bis orchestrierter Workflow-Integration.

germania-sacra
Prof. Dr. Hedwig Röckelein · M.A. Bärbel Kröger · Dr. Christian Popp
Fachliche Kuratierung, Editions-Expertise und Qualitätsstandards für historische Quellenkorpora.
Prof. Dr. Martin Baumeister · Dr. Jörg Hörnschemeyer
Leitender Anwendungsfall »Repertorium Germanicum«: praxisnahe Validierung und Zugang zu zentralen Quellen der spätmittelalterlichen Kirchengeschichte.
Prof. Dr. Martin Mulsow · Dr. Olaf Simons
Betrieb und Weiterentwicklung von FactGrid/Wikibase als domänenspezifischer Datenspeicher für kollaborative Erschließung und Abfrage.
Fragen, Kooperationen oder Fallstudien? Besuchen Sie unsere Kontaktseite oder eröffnen Sie ein Issue.
Ein Projekt zur modellhaften Erfassung historischer Daten in einer offenen Wissensdatenbank.
Die manuelle Annotation von Regesten dient als Grundlage für das Validieren und Entwickeln automatischer Extraktionsverfahren. Sie ist ein wichtiger Baustein unseres Forschungsprojekts, der die Qualität der nachfolgenden Pipelineschritte maßgeblich beeinflusst.
